

Okay, so Part 4 I maybe bit off more than I could chew. What we have left to do is:
- Adding article meta data
- Protecting against security threats
- Search Engine Optimisation
- Feedback from users
This in itself is already alot to take in and some very big subjects. Let’s start by protecting against security threats. I’ve noticed some strange logs in apache2 so likely my site is being probed and I’m usually wary about ways to attack the site when I’m building and also showing users my PHP code.
Protecting against security threats
The biggest threat is of course however wordpress (or maybe my own programming!), I don’t know the in’s and out’s of this complex beast and can’t dedicate time to fully know it. I did find this article though:
https://www.wpbeginner.com/wp-tutorials/9-most-useful-htaccess-tricks-for-wordpress/
Approach 2 I liked as my IP will change so opted for this. I didn’t find the article too helpful in it’s basic .htaccess code so opted for the basic one shown here:
This worked out pretty well and it didn’t disrupt anything so I opted to apply this across the board to any directories not needed to be directly accessible. Even when I locked down my PHP directory it didn’t interrupt my websites operation. Okay so that seemed suitable enough. I also added to disable indexing of my directories, I also implemented steps 5 and 9 as well as easy solutions to start locking things down.
Even setting this up ran into a few issues with overall accesses so I have opted to stop there with the whole security setup. I know I could validate my PHP form data to ensure no SQL Injections happen… Damn, okay I’ll do it. I found this article which makes it seem simple enough:
https://stackoverflow.com/questions/60174/how-can-i-prevent-sql-injection-in-php
Thankfully there is only two PHP files which take any input which has an impact on the SQL commands executed. Everything else is a get of some kind. Even better, when I look at my counter.php it only pulls data from the server itself so that one is already fine, leaving only one part – the recent subscribe function. Wow, up until yesterday, it was all secure. So let’s go and update that script.
It was quite ironic, I spent a while thinking my bind_params was not working when in fact it was an error message because my if for success or unsuccess output was not reset for the new output in this method. Anyway, this is the code I ended up with on my unsubscribe:
<?php
$link = new mysqli("localhost", "root", "", "MyContent");
// Check connection
if($link === false){
die("ERROR: Could not connect. " . mysqli_connect_error());
}
$stmt = mysqli_prepare($link, "DELETE FROM subscribers WHERE email = ?");
mysqli_stmt_bind_param($stmt, 's', $email);
$email = $_GET['email'];
mysqli_stmt_execute($stmt);
$stmt->store_result();
if($stmt->affected_rows){
echo "Unsubscribed successfully. Sorry to see you go, come back soon!";
} else{
echo "ERROR: Could not able to execute $sql. " . mysqli_error($link);
}
// Close connection
mysqli_close($link);
?>So that’s an example of how that works.
Adding article meta data/Search Engine Optimization
I’ve bundled these two subjects because they are effectively the same. A search engine rates you on your meta data as a big factor. What I also really wanted was a way to score my progress and I found upon this extension for google chrome:
As you can see, I’ve done alot of work already on my index page:
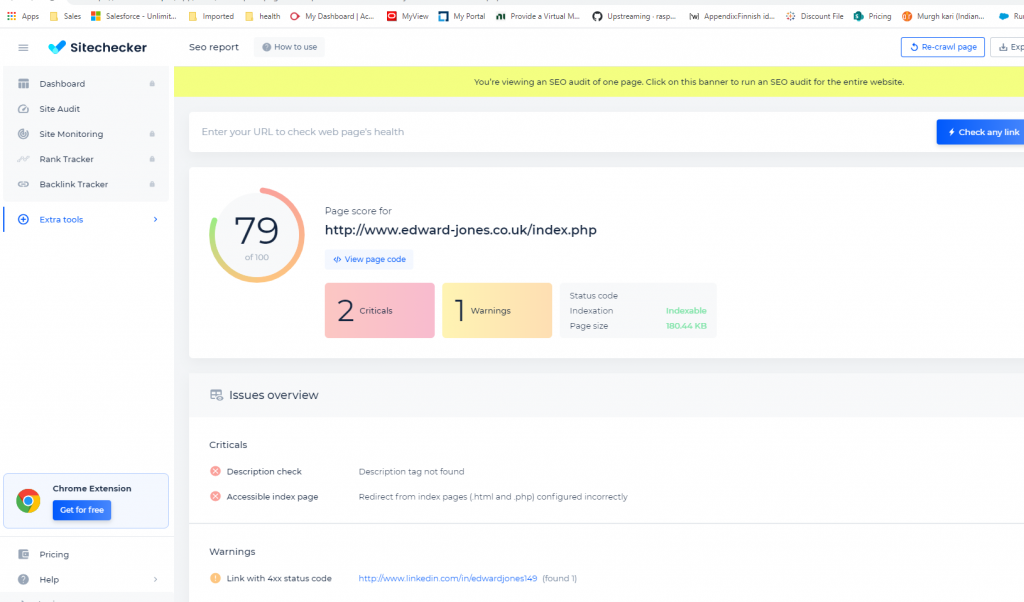
As you can see, my about page has a far lower score as I mainly focused on the index page:
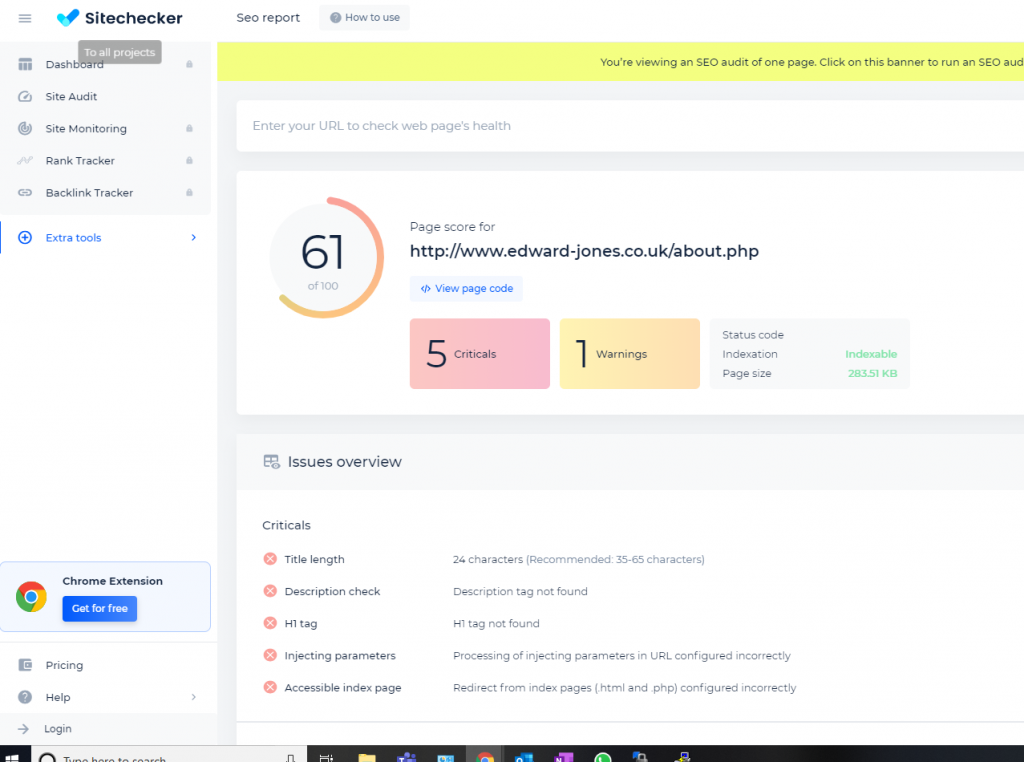
So we want to automate a few things. Firstly, I learned from reading several articles that I should ensure only one link per page with canonical declarations, I should include meta tags and have alternative text for images. I’ll do my best but this is a lot of admin. So I’ll mainly work by building PHP scripts which embed this information anyway, some will be universal and some will be specific. As an example, I embed into my articles tags, I can simply use those as my meta keywords.
First though, let’s talk about robots.txt as that is at the heart of SEO. We do want to be crawled and findable by others but not everything of course. Even having the file indicates to a search engine that you care about things so it’s always good to create one even if it’s empty.
The main things I learned from reading this:
https://developers.google.com/search/docs/advanced/robots/create-robots-txt
And of course, why wouldn’t google be the best resource for this. So I generated a sitemap using this link:
And then created my robots.txt:
# Group 1
User-agent: Googlebot
Disallow: /nogooglebot/
# Group 2
User-agent: *
Allow: /
Disallow: /blog/*
Disallow: /cgi-bin/*
Disallow: /js/*
Disallow: /php/*
Disallow: /vendor/*
Disallow: /yocto/*
Sitemap: http://www.edward-jones.co.uk/sitemap.xmlThe sitemap doesn’t naturally bring up all the links in it’s crawl, for now, I’m okay with that, I just need it so I rank higher. It’s also a good idea to regularly update this file.
For my index page, this is the meta data and conical linking I ended up with:
<meta name="description" content="Welcome to my portfolio! This is an accumulation of my projects that I believe are noteworthy or undocumented in their current fashion and deserve a place where they can be shared with the world.">
<meta name="keywords" content="HTML, CSS, JavaScript, PHP, jQuery, MySQL, Yocto, C#, C, C++, Linux, NI, LabVIEW, TestStand, Jenkins, Github, Git, Gitlab">
<meta name="googlebot" content="noarchive" />
<meta name="robots" content="noarchive" />
<meta name="author" content="Edward Jones">
<meta property="og:title" content="My Portfolio Website - Edward Jones" />
<meta property="og:description" content="My portfolio website! Where I exhibit alot of coding tutorials as well as experiences in achieving a task." />
<meta property="og:type" content="website" />
<meta property="og:url" content="http://www.edward-jones.co.uk" />
<meta property="og:image" content="http://www.edward-jones.co.uk/front.png" />
<link rel="canonical" href="http://www.edward-jones.co.uk" />
So of this seems fairly auto-generatable, like the URL for instance. We could use my previous trick in other articles of getting that from the server. Some are also fixed like website as type, author, robots, googlebot, title for most pages and image I’ll keep the same as well as description for the most part. The only things I’ll change out of this is that when you’re on the category page, keywords will populate with all tags from the articles within that category. Similarly, for an article page it will only populate with the tags for that article. The image on an article page will be the article’s thumbnail and the description will be an excerpt of the first 100 words.
So let’s add this across my main pages. Let’s move it to a template html file and then just include it via php. I’m going to use a trick I learned from here in a previous article:
https://stackoverflow.com/questions/45032803/php-sprintf-html-template
In this way, I end up with a few variables I need to manage:
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta name="description" content="{description}">
<meta name="author" content="Edward Jones">
<title>{title}</title>
<meta name="description" content="{description}">
<meta name="keywords" content="{keywords}">
<meta name="googlebot" content="noarchive" />
<meta name="robots" content="noarchive" />
<meta name="author" content="Edward Jones">
<meta property="og:title" content="{title}" />
<meta property="og:description" content="{description}" />
<meta property="og:type" content="website" />
<meta property="og:url" content="{url}" />
<meta property="og:image" content="{image}" />
<link rel="canonical" href="{url}" />
Unless the page is a category or article page, most of this should be quite static. With that in mind, let’s create a MySQL Table for this and populate that data from there. So let’s go create it:
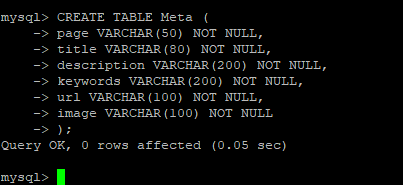
I then insert my index page meta data as follows:
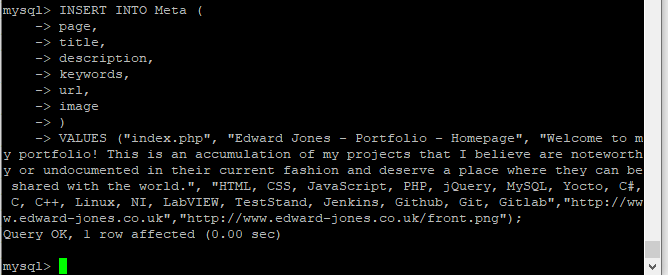
Now I needed to find my pagename which turned out simplistic via:
https://stackoverflow.com/questions/13032930/how-to-get-current-php-page-name
I finally after some playing around ended up on this code:
<?php
$db_host = 'localhost';
$db_username = 'root';
$db_password = '3Dzwftjb';
$db_name = 'MyContent';
$db_table = 'Meta';
// Create connection
$conn = new mysqli ($db_host, $db_username, $db_password, $db_name) or die("Host or database not accessible");
// Check connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
$sql = "SELECT * FROM Meta WHERE page = '" . basename($_SERVER['PHP_SELF']) . "'";
$result = $conn->query($sql);
$desc = "";
$title = "";
$key = "";
$url = "";
$img = "";
if ($result->num_rows > 0) {
// output data of each row
while($row = $result->fetch_assoc()) {
$desc = $row['description'];
$title = $row['title'];
$key = $row['keywords'];
$url = $row['url'];
$img = $row['image'];
}
}
//$row = mysql_fetch_assoc($result);
//echo $row->description;
//echo "Herro";
$body = file_get_contents("/var/www/public_html/templates/meta_auto.html");
$patterns = array(
'/{description}/',
'/{keywords}/',
'/{title}/',
'/{url}/',
'/{image}/',
);
$replacements = array(
$desc,
$key,
$title,
$url,
$img
);
$body2 = preg_replace($patterns, $replacements, $body);
echo $body2;
?>Now I can dynamically add my data… to some extent. What I want is that if this is unrecognised, just populate the index page data. And also, if it’s an article or category page as I mentioned before, be specific for those. To do it when I don’t have any answer I solved it by this:
<?php
$db_host = 'localhost';
$db_username = 'root';
$db_password = '3Dzwftjb';
$db_name = 'MyContent';
$db_table = 'Meta';
// Create connection
$conn = new mysqli ($db_host, $db_username, $db_password, $db_name) or die("Host or database not accessible");
// Check connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
$sql = "SELECT * FROM Meta WHERE page = '" . basename($_SERVER['PHP_SELF']) . "'";
$result = $conn->query($sql);
$desc = "";
$title = "";
$key = "";
$url = "";
$img = "";
if ($result->num_rows > 0) {
// output data of each row
while($row = $result->fetch_assoc()) {
$desc = $row['description'];
$title = $row['title'];
$key = $row['keywords'];
$url = $row['url'];
$img = $row['image'];
}
}else{
$sql = "SELECT * FROM Meta WHERE page = 'index.php'";
$result = $conn->query($sql);
while($row = $result->fetch_assoc()) {
$desc = $row['description'];
$title = $row['title'];
$key = $row['keywords'];
$url = $row['url'] . "/" . basename($_SERVER['PHP_SELF']);
$img = $row['image'];
}
}
$body = file_get_contents("/var/www/public_html/templates/meta_auto.html");
$patterns = array(
'/{description}/',
'/{keywords}/',
'/{title}/',
'/{url}/',
'/{image}/',
);
$replacements = array(
$desc,
$key,
$title,
$url,
$img
);
$body2 = preg_replace($patterns, $replacements, $body);
echo $body2;
?>Okay, now I need to be specific per article or per category. Later I can add to the MySQL database for each page and that will populate, for now, I’m more focused on the dynamic loading of this meta data rather than the admin behind it.
Since all my addresses should be at the root public_html directory I’m also gonna update my canonical link as above is shown. The next key part now is to grab my keywords. Recopying some of my code from my category page I could pull this data in and checking with postman, but found:
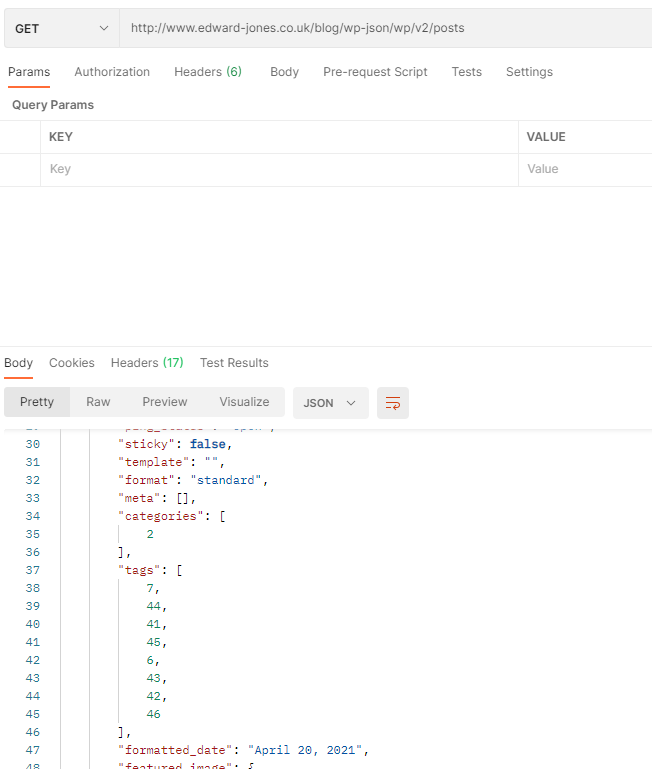
Tags are their own entity and I can only grab the ID’s, I need to then grab that info from the URL mentioned here:
I don’t want to get duplicates so let’s start by grabbing this data and removing duplicates. Well, turns out it’s very easy:
https://www.php.net/manual/en/function.array-unique.php
I had a bit of trouble with the array functions, if the initial array is empty for instance, array merge returns null. Array unique removes values but doesn’t update the keys so iterating through it can be problematic. I opted for this solution for that one:
https://stackoverflow.com/questions/21763200/php-array-unique-not-working-as-expected
So now I have all my unique tags as ID’s, time to get the actual values and then add them to my keywords variable. Then we should be finished up for the category’s page and just need to do the article page. After some work, this is what I came up with:
$emparray = array();
if(basename($_SERVER['PHP_SELF']) == "category.php")
{
if(isset($_GET['id'])){
$json = file_get_contents('http://www.edward-jones.co.uk/blog/wp-json/wp/v2/posts?categories=' . $_GET['id']);
$url = $url . "?id=" . $_GET['id'];
}else{
$json = file_get_contents('http://www.edward-jones.co.uk/blog/wp-json/wp/v2/posts');
}
$posts = json_decode($json);
foreach ($posts as $p) {
foreach ($p->tags as $t) {
array_push($emparray,$t);
}
}
$emparray = array_unique($emparray);
$emparray = array_values($emparray);
$key = "";
foreach($emparray as $tag){
$json = file_get_contents('http://www.edward-jones.co.uk/blog/wp-json/wp/v2/tags/' . $tag);
$tagg = json_decode($json);
$key = $key . $tagg->name . ", ";
}
$key = substr($key, 0, -2);
}
Now my keywords pop up in my category page:
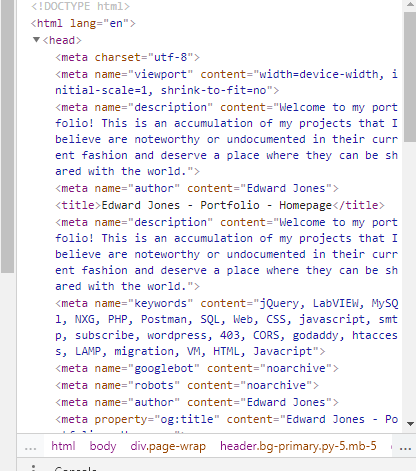
Now for the final page, articles. So let’s update some of this meta data, we’ll have the title of the page change as well, the url will be the specific url as it contains the id too. The description will be a substr of the first 100-200 characters, the keywords of course will be our tags as well. The next part was easy and just a mash up of all the things I’ve done before, I did notice that wordpress embeds things with ” whereas when I embedded this into the description, I had to change the content field to encapsulate it with single quotes instead otherwise it would cause an escape and corrupt the html.
if(basename($_SERVER['PHP_SELF']) == "article.php")
{
if(isset($_GET['id'])){
$key = "";
$check = 'http://www.edward-jones.co.uk/blog/wp-json/wp/v2/posts/' . $_GET['id'];
$json = file_get_contents($check);
$p = json_decode($json);
foreach($p->tags as $tag){
$json = file_get_contents('http://www.edward-jones.co.uk/blog/wp-json/wp/v2/tags/' . $tag);
$tagg = json_decode($json);
$key = $key . $tagg->name . ", ";
}
$key = substr($key, 0, -2);
$title = $p->title->rendered;
$url = $url . "?id=" . $_GET['id'];
$desc = substr($p->content->rendered, 0, 150);
} else
{
die("Error: No article id selected.");
}
}
My score on the SEO report was again not so great but at least it had this unique data now. It mostly now nit-picked at a few things so I was happy to end it there.
Now for the final bit right? Feedback from users… well, I’ve decided not to pursue that at this time. Woops! Guess you’ll have to contact me via the contact page for feedback for now :P.